Tracking Progress in Natural Language Processing
Table of contents
English
- Automatic speech recognition
- CCG
- Common sense
- Constituency parsing
- Coreference resolution
- Data-to-Text Generation
- Dependency parsing
- Dialogue
- Domain adaptation
- Entity linking
- Grammatical error correction
- Information extraction
- Intent Detection and Slot Filling
- Keyphrase Extraction and Generation
- Language modeling
- Lexical normalization
- Machine translation
- Missing elements
- Multi-task learning
- Multi-modal
- Named entity recognition
- Natural language inference
- Part-of-speech tagging
- Paraphrase Generation
- Question answering
- Relation prediction
- Relationship extraction
- Semantic textual similarity
- Semantic parsing
- Semantic role labeling
- Sentiment analysis
- Shallow syntax
- Simplification
- Stance detection
- Summarization
- Taxonomy learning
- Temporal processing
- Text classification
- Word sense disambiguation
Vietnamese
- Dependency parsing
- Intent detection and Slot filling
- Machine translation
- Named entity recognition
- Part-of-speech tagging
- Semantic parsing
- Word segmentation
Hindi
Chinese
For more tasks, datasets and results in Chinese, check out the Chinese NLP website.
French
Russian
Spanish
Portuguese
Korean
Nepali
Bengali
Persian
Turkish
German
Arabic
This document aims to track the progress in Natural Language Processing (NLP) and give an overview of the state-of-the-art (SOTA) across the most common NLP tasks and their corresponding datasets.
It aims to cover both traditional and core NLP tasks such as dependency parsing and part-of-speech tagging as well as more recent ones such as reading comprehension and natural language inference. The main objective is to provide the reader with a quick overview of benchmark datasets and the state-of-the-art for their task of interest, which serves as a stepping stone for further research. To this end, if there is a place where results for a task are already published and regularly maintained, such as a public leaderboard, the reader will be pointed there.
If you want to find this document again in the future, just go to nlpprogress.com
or nlpsota.com in your browser.
Contributing
Guidelines
Results Results reported in published papers are preferred; an exception may be made for influential preprints.
Datasets Datasets should have been used for evaluation in at least one published paper besides the one that introduced the dataset.
Code We recommend to add a link to an implementation
if available. You can add a Code column (see below) to the table if it does not exist.
In the Code column, indicate an official implementation with Official.
If an unofficial implementation is available, use Link (see below).
If no implementation is available, you can leave the cell empty.
Adding a new result
If you would like to add a new result, you can just click on the small edit button in the top-right corner of the file for the respective task (see below).

This allows you to edit the file in Markdown. Simply add a row to the corresponding table in the same format. Make sure that the table stays sorted (with the best result on top). After you’ve made your change, make sure that the table still looks ok by clicking on the “Preview changes” tab at the top of the page. If everything looks good, go to the bottom of the page, where you see the below form.
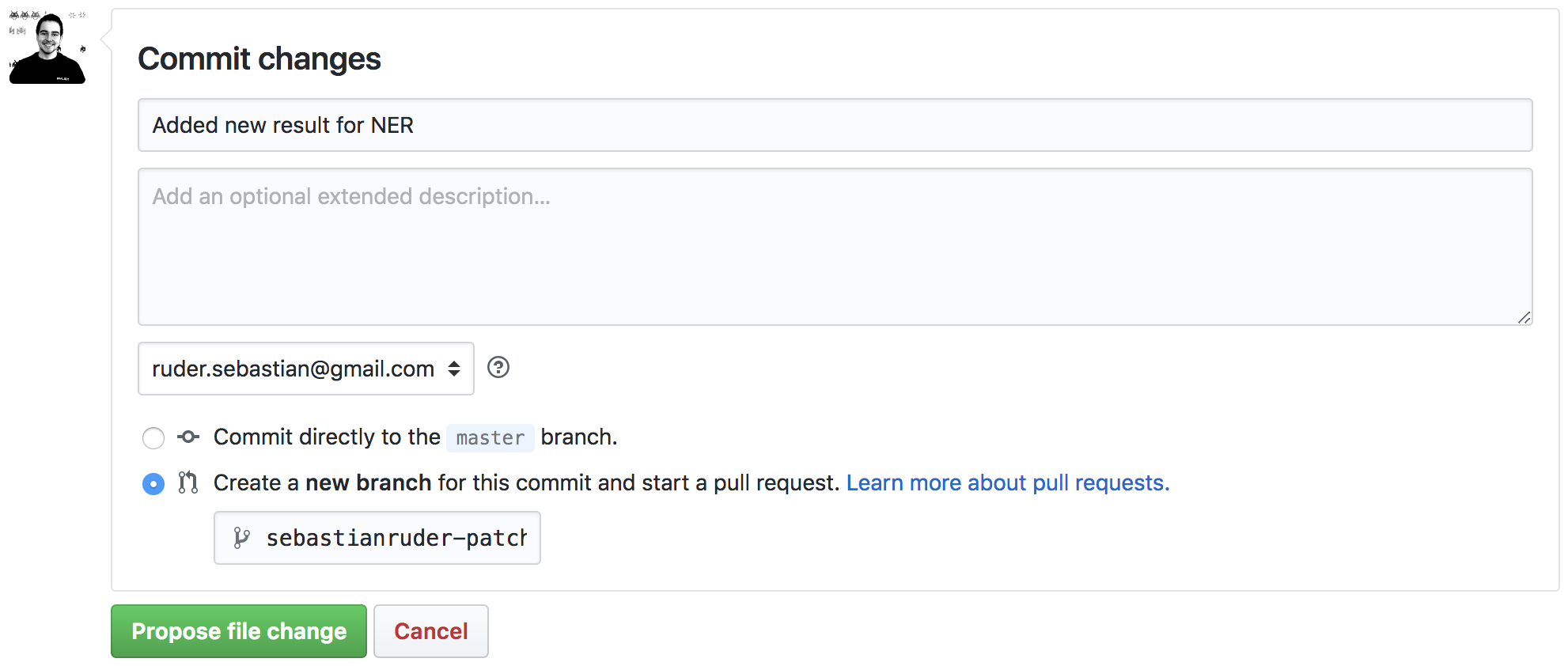
Add a name for your proposed change, an optional description, indicate that you would like to “Create a new branch for this commit and start a pull request”, and click on “Propose file change”.
Adding a new dataset or task
For adding a new dataset or task, you can also follow the steps above. Alternatively, you can fork the repository. In both cases, follow the steps below:
- If your task is completely new, create a new file and link to it in the table of contents above.
- If not, add your task or dataset to the respective section of the corresponding file (in alphabetical order).
- Briefly describe the dataset/task and include relevant references.
- Describe the evaluation setting and evaluation metric.
- Show how an annotated example of the dataset/task looks like.
- Add a download link if available.
- Copy the below table and fill in at least two results (including the state-of-the-art)
for your dataset/task (change Score to the metric of your dataset). If your dataset/task
has multiple metrics, add them to the right of
Score. - Submit your change as a pull request.
| Model | Score | Paper / Source | Code |
|---|---|---|---|
Wish list
These are tasks and datasets that are still missing:
- Bilingual dictionary induction
- Discourse parsing
- Keyphrase extraction
- Knowledge base population (KBP)
- More dialogue tasks
- Semi-supervised learning
- Frame-semantic parsing (FrameNet full-sentence analysis)
Exporting into a structured format
You can extract all the data into a structured, machine-readable JSON format with parsed tasks, descriptions and SOTA tables.
The instructions are in structured/README.md.
Instructions for building the site locally
Instructions for building the website locally using Jekyll can be found here.